搜索到
15
篇与
Web开发
的结果
-
 JAVA RMI GDC每小时触发Full GC 前言 最近倒腾Java,发现JVM并行收集器在还有大量堆内存的时候就开始触发老年代的回收,通过GC日志发现每小时都会执行GC和Full GC回收,回收是通过System.gc()调用。 那每小时都调用一次Full GC,我添加启动参数-Xms11g -Xmx11g分配11G堆内存只是为了好看吗?每次Full GC耗时在600ms,并行收集器老年代内存使用还不足5%,真是发神经了! 过程就不做记录了,无聊又蛋疼。以下是在使用了RMI或者其他NIO对象的情况。 RMI DGC每小时触发一次Full GC 原因:DGC代码中调用System.gc()导致并行收集器触发Full GC。 解决办法: 修改DGC调用System.gc()执行时间,默认一小时,单位ms。启动参数添加: -Dsun.rmi.dgc.client.gcInterval=3600000 -Dsun.rmi.dgc.server.gcInterval=3600000 禁止程序中的System.gc(),添加启动参数: -XX:+DisableExplicitGC 使用支持并发的收集器(CMS、G1、ZGC或Shenandoah),并且添加启动参数: -XX:+ExplicitGCInvokesConcurrent 方法1,治标不治本,延长时间触发Full GC会导致STW时间更长,可以配合并行收集器使用-XX:+ExplicitGCInvokesConcurrent来控制频率。 方法3,启用-XX:+ExplicitGCInvokesConcurrent参数可以尝试在垃圾收集时使用并发收集来减少STW时间,从而提高应用程序的响应性。 不建议使用-XX:+DisableExplicitGC来限制System.gc()。 因为从Java 7开始,Java提供了基于NIO的RMI实现,称为NIO-based RMI。这种实现利用了NIO的非阻塞I/O模型,能够更高效地处理大量的并发连接,减少了线程资源的消耗,并提高了性能和可伸缩性。通过使用NIO,NIO-based RMI能够更好地适应高并发和大规模的网络通信场景。 DirectByteBuffer是一种在堆外内存中分配的ByteBuffer,它与NIO密切相关,因为它可以直接映射到操作系统的内存中,从而避免了在Java堆和本地内存之间进行复制。在NIO编程中,使用DirectByteBuffer可以提高I/O操作的性能和效率,特别是在处理大量数据时。在基于NIO的RMI实现中,使用NioServerSocketChannel和NioEventLoopGroup通常涉及到DirectByteBuffer的使用。 虽然 DirectByteBuffer 对象本身是由 JVM 管理的,它们存储在 Java 堆内存中,但是 DirectByteBuffer 对象所持有的实际数据存储在堆外内存中。 JVM 通过 DirectByteBuffer 对象来管理对堆外内存的访问和操作。当 DirectByteBuffer 对象被垃圾回收时,它所持有的堆外内存也会随之被释放。 因此,触发 Full GC 通常是为了回收已经失去引用的 DirectByteBuffer 对象,进而释放掉它们所占用的堆外内存。 Full GC 在回收过程中会扫描整个堆内存,包括其中的对象和引用。当发现 DirectByteBuffer 对象已经没有引用指向时,JVM 就会将其标记为可回收, 待下次 Full GC 执行时进行回收。这样,间接地通过 Full GC 回收了 DirectByteBuffer 对象,也就释放了相应的堆外内存。 如果禁用了System.gc(),那么不会及时的清理 DirectByteBuffer 或者其他 NIO 对象导致堆外内存也不会释放。虽然最后也可能因为JVM堆内内存不足触发Full GC 来释放,但没必要冒险。参阅 监控程序调用System.gc()堆栈 可以使用 async-profiler 跟踪System.gc调用者: 预先开始分析: profiler.sh start -e java.lang.System.gc <pid> 发生一种或多种System.gc情况后,停止分析并打印堆栈跟踪: --- Execution profile --- Total samples : 6 Frame buffer usage : 0.0007% --- 4 calls (66.67%), 4 samples [ 0] java.lang.System.gc [ 1] java.nio.Bits.reserveMemory [ 2] java.nio.DirectByteBuffer.<init> [ 3] java.nio.ByteBuffer.allocateDirect [ 4] Allocate.main --- 2 calls (33.33%), 2 samples [ 0] java.lang.System.gc [ 1] sun.misc.GC$Daemon.run 在上面的示例中,System.gc从两个地方调用了 6 次。这两种情况都是 JDK 内部强制进行垃圾回收的典型情况。第一个来自java.nio.Bits.reserveMemory.当没有足够的可用内存来分配新的直接 ByteBuffer 时(由于-XX:MaxDirectMemorySize限制), JDK 会强制进行 Full GC 回收无法访问的直接 ByteBuffer。 第二个来自 GC Daemon 线程。这由 Java RMI 运行时定期调用。例如,如果您使用 JMX 远程,则每小时自动启用一次定期 GC。 这可以 通过-Dsun.rmi.dgc.client.gcInterval系统属性进行调整。 结语 起初我很不明白为什么DGC代码里面会有System.gc(),我一直以为堆外内存不归JVM管理,那调用System.gc()又有什么用呢?又是问ChatGPT又是各种搜索,才发现虽然JVM不管理堆外内存,但是管理使用堆外内存的对象,System.gc()是为了及时释放掉不再使用的堆外内存持有对象,堆内释放了,操作系统就会释放堆外内存了!
JAVA RMI GDC每小时触发Full GC 前言 最近倒腾Java,发现JVM并行收集器在还有大量堆内存的时候就开始触发老年代的回收,通过GC日志发现每小时都会执行GC和Full GC回收,回收是通过System.gc()调用。 那每小时都调用一次Full GC,我添加启动参数-Xms11g -Xmx11g分配11G堆内存只是为了好看吗?每次Full GC耗时在600ms,并行收集器老年代内存使用还不足5%,真是发神经了! 过程就不做记录了,无聊又蛋疼。以下是在使用了RMI或者其他NIO对象的情况。 RMI DGC每小时触发一次Full GC 原因:DGC代码中调用System.gc()导致并行收集器触发Full GC。 解决办法: 修改DGC调用System.gc()执行时间,默认一小时,单位ms。启动参数添加: -Dsun.rmi.dgc.client.gcInterval=3600000 -Dsun.rmi.dgc.server.gcInterval=3600000 禁止程序中的System.gc(),添加启动参数: -XX:+DisableExplicitGC 使用支持并发的收集器(CMS、G1、ZGC或Shenandoah),并且添加启动参数: -XX:+ExplicitGCInvokesConcurrent 方法1,治标不治本,延长时间触发Full GC会导致STW时间更长,可以配合并行收集器使用-XX:+ExplicitGCInvokesConcurrent来控制频率。 方法3,启用-XX:+ExplicitGCInvokesConcurrent参数可以尝试在垃圾收集时使用并发收集来减少STW时间,从而提高应用程序的响应性。 不建议使用-XX:+DisableExplicitGC来限制System.gc()。 因为从Java 7开始,Java提供了基于NIO的RMI实现,称为NIO-based RMI。这种实现利用了NIO的非阻塞I/O模型,能够更高效地处理大量的并发连接,减少了线程资源的消耗,并提高了性能和可伸缩性。通过使用NIO,NIO-based RMI能够更好地适应高并发和大规模的网络通信场景。 DirectByteBuffer是一种在堆外内存中分配的ByteBuffer,它与NIO密切相关,因为它可以直接映射到操作系统的内存中,从而避免了在Java堆和本地内存之间进行复制。在NIO编程中,使用DirectByteBuffer可以提高I/O操作的性能和效率,特别是在处理大量数据时。在基于NIO的RMI实现中,使用NioServerSocketChannel和NioEventLoopGroup通常涉及到DirectByteBuffer的使用。 虽然 DirectByteBuffer 对象本身是由 JVM 管理的,它们存储在 Java 堆内存中,但是 DirectByteBuffer 对象所持有的实际数据存储在堆外内存中。 JVM 通过 DirectByteBuffer 对象来管理对堆外内存的访问和操作。当 DirectByteBuffer 对象被垃圾回收时,它所持有的堆外内存也会随之被释放。 因此,触发 Full GC 通常是为了回收已经失去引用的 DirectByteBuffer 对象,进而释放掉它们所占用的堆外内存。 Full GC 在回收过程中会扫描整个堆内存,包括其中的对象和引用。当发现 DirectByteBuffer 对象已经没有引用指向时,JVM 就会将其标记为可回收, 待下次 Full GC 执行时进行回收。这样,间接地通过 Full GC 回收了 DirectByteBuffer 对象,也就释放了相应的堆外内存。 如果禁用了System.gc(),那么不会及时的清理 DirectByteBuffer 或者其他 NIO 对象导致堆外内存也不会释放。虽然最后也可能因为JVM堆内内存不足触发Full GC 来释放,但没必要冒险。参阅 监控程序调用System.gc()堆栈 可以使用 async-profiler 跟踪System.gc调用者: 预先开始分析: profiler.sh start -e java.lang.System.gc <pid> 发生一种或多种System.gc情况后,停止分析并打印堆栈跟踪: --- Execution profile --- Total samples : 6 Frame buffer usage : 0.0007% --- 4 calls (66.67%), 4 samples [ 0] java.lang.System.gc [ 1] java.nio.Bits.reserveMemory [ 2] java.nio.DirectByteBuffer.<init> [ 3] java.nio.ByteBuffer.allocateDirect [ 4] Allocate.main --- 2 calls (33.33%), 2 samples [ 0] java.lang.System.gc [ 1] sun.misc.GC$Daemon.run 在上面的示例中,System.gc从两个地方调用了 6 次。这两种情况都是 JDK 内部强制进行垃圾回收的典型情况。第一个来自java.nio.Bits.reserveMemory.当没有足够的可用内存来分配新的直接 ByteBuffer 时(由于-XX:MaxDirectMemorySize限制), JDK 会强制进行 Full GC 回收无法访问的直接 ByteBuffer。 第二个来自 GC Daemon 线程。这由 Java RMI 运行时定期调用。例如,如果您使用 JMX 远程,则每小时自动启用一次定期 GC。 这可以 通过-Dsun.rmi.dgc.client.gcInterval系统属性进行调整。 结语 起初我很不明白为什么DGC代码里面会有System.gc(),我一直以为堆外内存不归JVM管理,那调用System.gc()又有什么用呢?又是问ChatGPT又是各种搜索,才发现虽然JVM不管理堆外内存,但是管理使用堆外内存的对象,System.gc()是为了及时释放掉不再使用的堆外内存持有对象,堆内释放了,操作系统就会释放堆外内存了! -
LXK0301京东签到脚本-京喜工厂解决无法签到异常 前言 LXK0301大佬的京喜工厂自动签到脚本不知怎么一直提示:亲,活动太火爆了,请稍后再试吧!,基本无法使用,任务也不自动做了。 上网查了一下,全是说黑号,真蛋疼。因为脚本无法做任务什么的,但是手动完全没有问题,根本不是黑号,网上一股脑说黑号。 我就不信邪,app能做任务脚本就不行,肯定是脚本有问题。 2021-03-25 第二次更新,已经不需要自己抓包获取签名参数了,脚本会在每次执行时自动获取签名参数。已经联系作者,等作者更新吧!(推荐使用作者脚本,修复了参团问题) 2021-03-25更新,今天更新了下脚本,应该可以获取自己的签名参数使用了,有时间的朋友可以测试一下!仓库地址:jd_scripts-orzlee 2021-03-23更新,自己获取签名的方法可能无效,作者已经跟新脚本,目前使用我提供的签名参数可以正常做任务和领取电力,后续可能还需要研究。更新作者脚本即可! 原因 最根本的原因就是脚本发送请求链接签名有问题,这个好像只针对了部分用户,有的用户没问题,有的就会一直提示:亲,活动太火爆了,请稍后再试吧!。 起初发现问题是在手机上用QuantumultX抓包京喜APP,点击地上的零件,再抓包脚本,然后找出usermaterial/PickUpComponent请求来对比。开始我还以为是cookie问题,我替换cookie重试请求还是太火爆错误,再重发一下抓包京喜APP的请求,依然成功。再替换替换脚本请求的url参数为抓包app的,莫名奇妙的成功了。这个锅必须脚本背了! 脚本中decrypt函数是负责请求链接签名的,但是目前脚本有问题,很多签名key都是没有值的,因为根本没有获取值,只有少部分定义了默认值。来看一下代码(目前是1535行): function decrypt(time, stk, type) { if (stk) { const random = 'pmUmA8IyRcDp'; //这些常量其实每个用户都可能不一样 const token = `tk01wd4571d58a8nT0tkdXczeW94f5x4qjWs44kcPCTXeWKa2xXY+ZxHaOtbRxmyw6vrIF4RDFwwTUfwy1pIqNE0oyWW`; //这些常量其实每个用户都可能不一样 const fingerprint = 8410347712257161; //这些常量其实每个用户都可能不一样 //这个时间转换和现在的不一样,现在是new Date(time).Format("yyyyMMddhhmmssSSS");,转换结果不一样,加密出来也不一样 const timestamp = new Date(time).Format("yyyyMMddhhmmssS"); const appId = 10001; //这个是活动id 是固定的 const str = `${token}${fingerprint}${timestamp}${appId}${random}`; const hash1 = $.CryptoJS.HmacSHA512(str, token).toString($.CryptoJS.enc.Hex); //这里加密算法有可能不一样 let st = ''; stk.split(',').map((item, index) => { //下面的签名参数只有些默认值,很多都是空的,但是链接上又带了有效值,服务器验签估计不合法(但是有的用户却没有问题,搞不懂) st += `${item}:${item === '_time' ? time : item === 'zone' ? 'dream_factory' : item === 'type' ? type || '1' : ''}${index === stk.split(',').length -1 ? '' : '&'}`; }) const hash2 = $.CryptoJS.HmacSHA256(st, hash1).toString($.CryptoJS.enc.Hex); console.log(`st:${st}\n`) // console.log(`hash2:${JSON.stringify(["".concat(timestamp.toString()), "".concat(fingerprint.toString()), "".concat(appId.toString()), "".concat(token), "".concat(hash2)])}\n`) console.log(`h5st:${["".concat(timestamp.toString()), "".concat(fingerprint.toString()), "".concat(appId.toString()), "".concat(token), "".concat(hash2)].join(";")}\n`) return ["".concat(timestamp.toString()), "".concat(fingerprint.toString()), "".concat(appId.toString()), "".concat(token), "".concat(hash2)].join(";") } else { return '20210121201915905;8410347712257161;10001;tk01wa5bd1b5fa8nK2drQ3o3azhyhItRUb1DBNK57SQnGlXj9kmaV/iQlhKdXuz1RME5H/+NboJj8FAS9N+FcoAbf6cB;3c567a551a8e1c905a8d676d69e873c0bc7adbd8277957f90e95ab231e1800f2' } } 研究过程我就不再多说了,京东那边全是混淆的JS,真的很头疼,我弄了一下午才摸清楚他的逻辑。 整个流程大概是这样(官方的js混淆了,乱七八糟的就不贴代码了): 第一次进入活动页面会发送POST请求:https://cactus.jd.com/request_algo?g_ty=ajax,将返回结果储存在本地(这个默认应该没有有效期,但是京喜工厂里面的JS会设置有效期,过期会重新获取)。已经更新脚本自动获取签名参数了。 请求参数: { appId: "10001" expandParams: "" //fingerprint //pc浏览器我试过,就算拿到所有数据跑脚本依然不行,还是太火爆错误。所以保险还是去京喜APP抓包吧! fp: "5525701123405161" platform: "web" timestamp: 1614687205087 version: "1.0" } 接口会返回: { data: { result: { //加密函数 algo: "function test(token,fingerprint,timestamp,appId,algo){const random='jQ1SS0VI2Vuw';const str=`${token}${fingerprint}${timestamp}${appId}${random}`;return algo.SHA512(str)}" //加密token tk: "tk01w91541b51a8nWURUM3hiZk9HHRKep5j4FeOg/jHOQoGSDcsasdSOZ+83iz4uf/YBXHcK6xMIUqqv5/iJv6F0aooT5Nd3" } version: "1.0" message: "" status: 200 } } 这个接口会返回所有签名需要的参数,也就是脚本中decrypt中的参数,其实照着值样子都知道怎么替换了。 当前时间格式转换new Date(time).Format("yyyyMMddhhmmssSSS")这个时间是和链接参数中的'_time匹配'。 字符串拼接${token}${fingerprint}${timestamp}${appId}${random}。 第一次签名,将第三步的字符串用SHA或者MD5加密,这个主要参考第一步中的机密函数: function test(token,fingerprint,timestamp,appId,algo){ const random='jQ1SS0VI2Vuw'; const str=`${token}${fingerprint}${timestamp}${appId}${random}`; return algo.SHA512(str) } 这个函数提供了加密方法和随机字符串,官方直接用它做闭包函数第一次签名。 第一次签名完成后,开始第二次了,这个参数每个接口可能不同,它会按照请求url中的_stk参数来提供签名参数,例如&_stk=_time,pin,placeId,zone,那么就需要将参数拼接成time:xxxx&pin:xxxx&placeId:xxxx&zone:xxx这样子。stk参数的值也会包含在url中,例如: https://m.jingxi.com/dreamfactory/usermaterial/PickUpComponent?zone=dream_factory&placeId=1&pin=91DCBu8VvYt6rEdezHZ_VQ%3D%3D&_time=1614622722731&_stk=_time%2Cpin%2CplaceId%2Czone&_ste=1&h5st=20210302021842732%3B6099600123439161%3B10001%3Btk01wa66691cafa8nSmV1UDN2SWtZAiPI1uR1EAuPwYDaw36v9gQGhJz5Ac4h2cjfkeCQexVweqwa6%2BsjvERwkVU6wxTK%3Ba795we798qwe789789qe8262584d49f9449a1ce0194bb26c72049eef428f5e23e1043a641d&_=1614622722744&sceneval=2&g_login_type=1&callback=jsonpCBKR&g_ty=ls 第二次签名加密的算法是固定的,SHA256。 最后拼接: ["".concat(timestamp.toString()), "".concat(fingerprint.toString()), "".concat(appId.toString()), "".concat(token), "".concat(hash2)].join(";") 抓包 2021-03-04 更新可以免去抓包和修改脚本操作了: 一旦有一个设备的url签名参数更新,其他设备都会失效,如果多设备跑同一个账号要保持一直,否则还是会失败的!!! 我更新了脚本,不需要手动抓包了,QuantumultX可以添加url_sign_params.conf重写引用,其他平台可能需要自己写一下。然后删除京喜APP,重新下载后进入京喜工厂(最好重下APP,不然有可能还是太火爆异常,如果没有提示退出京喜工厂再进一次,多试试!): 折腾好了就只使用京喜APP进入京喜工厂(url签名参数会被京喜工厂里面的JS设置过期时间,过期会重新获取),以免从京东APP进入京喜工厂跳转到京喜APP重新获取覆盖,京东APP里面的京喜工厂获取的url签名参数也不能执行成功!只能使用京喜APP的url签名参数! 日志可以查看url签名参数: 以下为未更新之前的方法: 找到了问题就好解决了,抓包京喜APP一个请求就行了,抓包之前建议先删除APP,因为签名参数会存在本地,基本上弄不到了。删掉APP再进入京喜工厂之前,准备好抓包工具,IOS可以用QuantumultX、Surge等,PC抓包太多了,一搜一大把。 准备好抓包工具之后,进入京喜工厂,等待完全进入工厂,最好再捡下零件。没有报错就可以关掉抓包工具了。 搜索algo,找到签名参数请求: 请求JSON和响应JSON都要看,不然你不知道fingerprint参数,是一串数字,在请求JSON里: 复制返回请求中的参数: 修改脚本 脚本我修改了很多处,但是很简单: 新增一个获取url参数的函数: /** * 新增url参数获取函数 * @param url_string * @param param * @returns {string|string} */ function getUrlQueryParams(url_string, param) { let url = new URL(url_string); let data = url.searchParams.get(param); return data ? data : ''; } 时间函数与官方不一致,会导致签名结果错误(这函数是官方混淆JS里面扒出来的): /* 修改时间戳转换函数,京喜工厂原版修改 */ Date.prototype.Format = function (fmt) { var e, n = this, d = fmt, l = { "M+": n.getMonth() + 1, "d+": n.getDate(), "D+": n.getDate(), "h+": n.getHours(), "H+": n.getHours(), "m+": n.getMinutes(), "s+": n.getSeconds(), "w+": n.getDay(), "q+": Math.floor((n.getMonth() + 3) / 3), "S+": n.getMilliseconds() }; /(y+)/i.test(d) && (d = d.replace(RegExp.$1, "".concat(n.getFullYear()).substr(4 - RegExp.$1.length))); for (var k in l) { if (new RegExp("(".concat(k, ")")).test(d)) { var t, a = "S+" === k ? "000" : "00"; d = d.replace(RegExp.$1, 1 == RegExp.$1.length ? l[k] : ("".concat(a) + l[k]).substr("".concat(l[k]).length)) } } return d; } decrypt函数也要修改,我加了一个url参数,在拼接签名参数需要的值可以在url中拿(实在不想动太多代码,怎么方便怎么来吧): /* 签名函数 签名信息获取地址:https://cactus.jd.com/request_algo?g_ty=ajax 方法: POST 参数:{ appId: "10001" expandParams: "" fp: "5525701123405161" //fingerprint platform: "web" timestamp: 1614687205087 version: "1.0" } 返回结果:{data: { result: { algo: "function test(token,fingerprint,timestamp,appId,algo){const random='jQ1SS0VI2Vuw';const str=`${token}${fingerprint}${timestamp}${appId}${random}`;return algo.SHA512(str)}" //加密函数 tk: "tk01w91541b51a8nWURUM3hiZk9HHRKep5j4FeOg/jHOQoGSDcsasdSOZ+83iz4uf/YBXHcK6xMIUqqv5/iJv6F0aooT5Nd3" //token } version: "1.0" message: "" status: 200 } } 将返回参数替换: const random : data.result.algo字符串中的const random='xxxxxx' const token : data.result.tk const fingerprint : 通过抓包APP获取 const hash1加密方法(例子:algo.SHA512、algo.MD5,主要看签名信息获取地址返回结果data.result.algo) */ function decrypt(time, stk, type, url) { stk = stk || (url ? getUrlQueryParams(url, '_stk') : '') if (stk) { const random = '1gy8nc5oDM+y'; const token = `tk01w9a771c1aa8nd1k2NUo4UmNaahBe0/qh61gMNV9222JdJwlR0wyO9gko9dFTogSpvPIpqxstZJ9tl8JM9ONKNJWk`; const fingerprint = 5525701217505161; const timestamp = new Date(time).Format("yyyyMMddhhmmssSSS"); const appId = 10001; const str = `${token}${fingerprint}${timestamp}${appId}${random}`; const hash1 = $.CryptoJS.HmacSHA512(str, token).toString($.CryptoJS.enc.Hex); let st = ''; stk.split(',').map((item, index) => { // st += `${item}:${item === '_time' ? time : item === 'zone' ? 'dream_factory' : item === 'type' ? type || '1' : ''}${index === stk.split(',').length -1 ? '' : '&'}`; st += `${item}:${getUrlQueryParams(url, item)}${index === stk.split(',').length -1 ? '' : '&'}`; }) const hash2 = $.CryptoJS.HmacSHA256(st, hash1).toString($.CryptoJS.enc.Hex); console.log(`st:${st}\n`) // console.log(`hash2:${JSON.stringify(["".concat(timestamp.toString()), "".concat(fingerprint.toString()), "".concat(appId.toString()), "".concat(token), "".concat(hash2)])}\n`) console.log(`h5st:${["".concat(timestamp.toString()), "".concat(fingerprint.toString()), "".concat(appId.toString()), "".concat(token), "".concat(hash2)].join(";")}\n`) return ["".concat(timestamp.toString()), "".concat(fingerprint.toString()), "".concat(appId.toString()), "".concat(token), "".concat(hash2)].join(";") } else { return '20210121201915905;8410347712257161;10001;tk01wa5bd1b5fa8nK2drQ3o3azhyhItRUb1DBNK57SQnGlXj9kmaV/iQlhKdXuz1RME5H/+NboJj8FAS9N+FcoAbf6cB;3c567a551a8e1c905a8d676d69e873c0bc7adbd8277957f90e95ab231e1800f2' } } 最后一步了,搜索${decrypt(关键字,大概有8处要修改,主要是团长这部分多,主要还是没有解耦: 参团部分(每一个api不一样,只要剥离出&h5st=${decrypt(xxxxx就行了,单独拼接): //可获取开团后的团ID,如果团ID为空并且surplusOpenTuanNum>0,则可继续开团 //如果团ID不为空,则查询QueryTuan() function QueryActiveConfig() { return new Promise((resolve) => { //option中的url拉出来替换如下 let url = `https://m.jingxi.com/dreamfactory/tuan/QueryActiveConfig?activeId=${escape(tuanActiveId)}&_time=${Date.now()}&_=${Date.now()}&sceneval=2&g_login_type=1&_ste=1` url += `&h5st=${decrypt(Date.now(), '', '', url)}` const options = { 'url': url, //改成变量 "headers": { ... taskurl和newtasksysUrl函数部分: function taskurl(functionId, body = '', stk) { let url = `${JD_API_HOST}/dreamfactory/${functionId}?zone=dream_factory&${body}&sceneval=2&g_login_type=1&_time=${Date.now()}&_=${Date.now()}&_ste=1` url += `&h5st=${decrypt(Date.now(), stk, '', url)}` if (stk) { url += `&_stk=${stk}`; } ... function newtasksysUrl(functionId, taskId, stk) { let url = `${JD_API_HOST}/newtasksys/newtasksys_front/${functionId}?source=dreamfactory&bizCode=dream_factory&sceneval=2&g_login_type=1&_time=${Date.now()}&_=${Date.now()}&_ste=1`; if (taskId) { url += `&taskId=${taskId}`; } if (stk) { url += `&_stk=${stk}`; } //传入url进行签名,加入位置不要错了,不然有些签名参数获取不到值 url += `&h5st=${decrypt(Date.now(), stk, '', url)}` ... 大功告成,发到手机上或者node跑一下试试: 结果非常完美。 docker处理 手机端好办,docker麻烦一点,放到远程或者本地都行,具体看说明jd_scripts docker。docker提供了一个环境变量CUSTOM_SHELL_FILE(你也可以用CUSTOM_LIST_FILE挂载本地定时任务列表,只是更新要手动,要自动还是需要脚本的)可以跑远程shell脚本,jd_scripts docker说明中还有示例,照葫芦画瓢即可。我在github上弄一份自用,你可以参考或者fork一份自己用,地址:jd_scripts-orzlee。只需替换decrypt函数部分常量就好了,shell脚本最好看看我写的注释。然后在环境变量中加入shell脚本地址CUSTOM_SHELL_FILE=https://raw.githubusercontent.com/xxx/xxx.sh即可。 如果用我仓库的远程脚本,务必docker配置环境变量RANDOM_DELAY_MAX=600, 600的值可以自己设置非零正整数,意思是所有脚本每天随机延迟0-600秒执行。 结语 经过不懈努力,终于还是折腾好了,这半个月都是手动点击脚本,人家升级都比我快,没办法手动哪里有脚本那么按时呢!混淆JS浪费不少时间,眼睛都能看瞎。
-
Vue-videoJS播放m3u8视频 前言 找到一部分M3U8视频源,之前用H5 video 标签播放MP4视频,但是支持视频格式很少,索性换掉算了。 M3U8简单了解 引用维基百科: M3U8是Unicode版本的M3U,用UTF-8编码。"M3U"和"M3U8M3U8"文件都是苹果公司使用的HTTP Live Streaming格式的基础,这种格式可以在iPhone和Macbook等设备播放。 引用知乎: 上述文字定义来自于维基百科。可以看到,m3u8 文件其实是 HTTP Live Streaming(缩写为 HLS) 协议的部分内容,而 HLS 是一个由苹果公司提出的基于 HTTP 的流媒体网络传输协议。 HLS 的工作原理是把整个流分成一个个小的基于 HTTP 的文件来下载,每次只下载一些。当媒体流正在播放时,客户端可以选择从许多不同的备用源中以不同的速率下载同样的资源,允许流媒体会话适应不同的数据速率。在开始一个流媒体会话时,客户端会下载一个包含元数据的 extended M3U (m3u8) playlist文件,用于寻找可用的媒体流。 HLS 只请求基本的 HTTP 报文,与实时传输协议(RTP)不同,HLS 可以穿过任何允许 HTTP 数据通过的防火墙或者代理服务器。它也很容易使用内容分发网络来传输媒体流。 简单理解,M3U8其实就是视频文件碎片索引URL(类似于播放列表),播放器会解析并且下载这些视频碎片,拼接成一整个视频。MP4格式对HTTP和Flash都比较友好,但是MP4文件头部结果比较复杂,播放过程对网络带宽要求较高,在网络复杂的场景用户体验较差。 Vue集成 集成之前大致了解了下,网上比较多的是vue-video-player和videojs,我选择了后者(之前video标签转过来还是不能跨度太大,免得拉跨)。 这东西让我折腾挺久的,只能怪自己懒,好好的文档不看,到处搜,结果搜到一堆复制粘贴的垃圾文章,也不知道什么年代的了,结果发布日期全是今年的。 官方文档相当简洁,其实非常简单,文档在此tutorial-vue,一目了然。 说说我的情况吧!,官方文档是在mounted方法中初始化播放器,但是我的视频流是动态加载的,这样直接加载会报错: CODE:4 MEDIA_ERR_SRC_NOT_SUPPORTED) No compatible source was found for this media 因为我的视频地址和视频类型都没有请求,只能在请求完成之后再初始化播放器。 播放器已经封装成组件了,看代码。 安装videojs: npm install --save video.js npm install --save @videojs/http-streaming //这个应该是不需要的,video.js在7.x就已经包含了,报错就还是加上吧,懒得试了 <template> <video ref="video" class="video-js" > <source :src="src" :type="video_type"> </video> </template> import Video from 'video.js' import '@videojs/http-streaming' import 'video.js/dist/video-js.css' //css要加载 export default { name: "playVideo", data: () => { return { player: null, } }, props: { width: { type: Number, default: 0, }, height: { type: Number, default: 0, }, src: { type:String, default: '', }, video_type: { type: String, default: 'video/mp4', } }, watch: { video_type(){ //监听props赋值,初始化播放器 this.initVideo(); } }, beforeDestroy() { //销毁不能少啊!!!!! if (this.player) { this.player.dispose() } }, methods: { pause() { this.$nextTick(function () { // DOM 现在更新了 // `this` 绑定到当前实例 this.$refs.video.pause(); }) }, initVideo() { //初始化视频方法 this.player = Video(this.$refs.video, { //确定播放器是否具有用户可以与之交互的控件。没有控件, //启动视频播放的唯一方法是使用autoplay属性或通过Player API。 controls: true, //自动播放属性,muted:静音播放 autoplay: "muted", //建议浏览器是否应在<video>加载元素后立即开始下载视频数据。 preload: "auto", //设置视频播放器的显示宽度(以像素为单位) width: this.width, //设置视频播放器的显示高度(以像素为单位) height: this.height, //网上很多没有用这个参数,默认获取<video><source src="" type=""/></video> //标签中的 source中的链接和类型,手动指定就可以避免动态获取视频信息的坑 sources: { src: this.src, //视频地址 type: this.video_type //视频类型 } }); } } } 结语 其实分分钟的是,搞了大半天。不过这个项目快一年没碰了,搞起来还有点懵逼。Graphql只用过一次,就是这项目上,Vue也好久没碰了,边熟悉边折腾,真是学无止尽啊。
-
Laravel-关系预加载数量限制 前言 最近开发一个项目,关于用户评论。评论可以被用户再次评论,当然只做了一级限制,没有做太多层级,可以回复某个评论中的特定用户(类似于@功能)。 在输出评论列表中,是应该输出部分评论的回复,但是看似简单,实际情况却相对复杂。 分析 在laravel中查询出两级并不难, 使用预加载可以轻松完成: class Comment extends Model { ... public function comments() { return $this->hasMany($this, 'comment_id'); } ... } Comment::with('comments')->simplePaginate() 当需要限制评论回复的数量时,首先想到的是如下方法: Comment::with( [ 'comments' => function (HasMany $query) { $query->take(5); }, ] )->simplePaginate() 但是返回的模型关系comments被限制小于等5条,并不是每条评论的回复,而是整个查询结果的评论回复。如果第一条评论回复有10条,那么会显示5条,之后其他评论的回复全部为空。 其中的Sql语句是这样: select * from `comments` where `comments`.`comment_id` in (1, 2, ...) limit 5 要实现每条评论显示N条回复并不难,只是回到了N + 1的问题, 查询出列表后再加载关系: $comments = Comment::simplePaginate(); $comments->each(function($comment) { $comment->load( [ 'comments' => function (HasMany $query) { $query->take(5); }, ] ); }); Sql: select * from `comments` where `comments`.`comment_id` in (1) limit 5 select * from `comments` where `comments`.`comment_id` in (2) limit 5 ... 这样确实可以解决问题,但是非常笨。 在laravel-framework的issue中找到了类似问题Eager-loading with a limit on collection...,其中有位开发者通过修改limit和take方法来实现预加载关系数量限制,但是提交PR被laravel作者拒绝,于是封装成扩展eloquent-eager-limit。 我安装后试了下,确实能达到效果,于是看了下源码。作者几乎把所有关系的limit和take方法全部重写,然后封装成Trait,模型中使用该Trait相当于重写了limit和take方法。使用方法和之前一样,但是要注意,一旦使用eloquent-eager-limit的Trait后,该模型就不再有之前关系limit或take的总限制效果了,相信laravel作者拒绝也是因为此原因。 来看看生成的语句: select laravel_table.*, @laravel_row := if(@laravel_partition = `comment_id`, @laravel_row + 1, 1) as laravel_row, @laravel_partition := `comment_id` from (select @laravel_row := 0, @laravel_partition := 0) as laravel_vars, (select * from `comments` where `comments`.`comment_id` in (1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16) order by `comments`.`comment_id` asc) as laravel_table having laravel_row <= 10 order by laravel_row; 从Sql语句看来确实只用两次查询就可以获得结果,比之前load遍历加载方法更优。 来看看最终效果: { "data": [ { "id": 1, "post_id": 2, "comment_id": null, "contents": "contents...", "created_at": "2020-12-21 09:31:26", "comments": [ { "id": 24, "post_id": 2, "comment_id": 1, "contents": "contents....", "created_at": "2020-12-22 10:21:40", ... }, { "id": 18, "post_id": 2, "comment_id": 1, "contents": "contents....", "created_at": "2020-12-22 10:18:10", ... }, ... ], }, { "id": 7, "post_id": 2, "comment_id": null, "contents": "contents....", "created_at": "2020-12-22 09:38:07", "comments": [ { "id": 13, "post_id": 2, "comment_id": 7, "contents": "contents....", "created_at": "2020-12-22 10:11:02", }, { "id": 8, "post_id": 2, "comment_id": 7, "contents": "contents....", "created_at": "2020-12-22 09:59:43", } ... ] }, ... ], ... "status": "success", "code": 200 结语 其实也可以手动写Sql语句,缩成一条语句查询。但是太过于复杂的Sql并不易于维护,而且性能并不是一次复杂查询就一定比两次查询快。损失一点性能提高代码可维护性还是赚的。如果项目用户量较大,就要考虑缓存等其他技术优化了。
-
Laradock-PHPStorm开启XDebug 前言 前几天写了一篇Laradock-部署本地开发环境,使用了几天发现确实很方便。最近又折腾点东西,没有XDebug确实不顺手,网上找了不少资料和教程,有些坑和解决方案记录一下。 开搞 开启XDebug 需要laradock容器php-fpm、workspace都安装XDebug,如果已经安装则不需要管它,否则需要修改你的laradock目录\.env。 PHP_FPM_INSTALL_XDEBUG=true WORKSPACE_INSTALL_XDEBUG=true PHP_IDE_CONFIG=serverName=laradock PHP_IDE_CONFIGXDebug服务名看你自己,你想改就改,不想改默认就行。 然后再重新build docker-compose build php-fpm workspace。每次build真心漫长,就一个扩展也要整个编译,这里不得不吐槽下。强烈建议科学上网或者修改laradock源地址(修改源地址我没有验证过,不会科学上网你可以试试): # If you need to change the sources (i.e. to China), set CHANGE_SOURCE to true CHANGE_SOURCE=true # Set CHANGE_SOURCE and UBUNTU_SOURCE option if you want to change the Ubuntu system sources.list file. UBUNTU_SOURCE=aliyun 配置xdebug.ini 两处都要修改你的laradock目录\workspace\xdebug.ini、你的laradock目录\php-fpm\xdebug.ini: //xdebug.remote_host="docker.for.win.host.internal" xdebug.remote_connect_back=1 xdebug.remote_port=9000 xdebug.idekey=PHPSTORM xdebug.remote_autostart=0 xdebug.remote_enable=0 xdebug.cli_color=0 xdebug.profiler_enable=0 xdebug.profiler_output_dir="~/xdebug/phpstorm/tmp/profiling" xdebug.remote_handler=dbgp xdebug.remote_mode=req xdebug.var_display_max_children=-1 xdebug.var_display_max_data=-1 xdebug.var_display_max_depth=-1 两种方法: 修改xdebug.remote_host值为Windows:docker.for.win.host.internal,MacOS:docker.for.mac.host.internal。xdebug.remote_connect_back修改为0。 注释掉xdebug.remote_host配置,不指定主机xdebug.remote_connect_back=1,让XDebug自动捕获主机。 网上很多教程说是改成xdebug.remote_host=docker.for.win.localhost或者xdebug.remote_host=docker.for.mac.localhost,这是之前的写法,巨坑。直接使用第二种方法省得坑爹。 默认xdebug.ini配置文件是不能动态修改的,每次修改都必须build,为了方便可以修改docker-compose.yml文件 ### Workspace Utilities ################################## workspace: build: context: ./workspace args: ... volumes: ... - ./workspace/xdebug.ini:/etc/php/${PHP_VERSION}/cli/conf.d/xdebug.ini ###添加磁盘挂载 ### PHP-FPM ############################################## php-fpm: build: context: ./php-fpm args: ... volumes: ... - ./php-fpm/xdebug.ini:/usr/local/etc/php/conf.d/xdebug.ini ###添加磁盘挂载 ... 这样修改后可以热修改文件,就像配置nginx站点一样方便 配置PHPStorm 新建一个服务,服务名称就是这里配置的PHP_IDE_CONFIG=serverName=laradock laradock,Host填写你本地站点访问地址,开启Use path mappings,填写你的映射地址/var/www/you-project,然后OK。 点击Run菜单: 点击+添加一个PHP Remote Debug: 勾选Filter debug connection by IDE key,选择你的刚刚添加的Server,IDE key填写PHPSTORM,这个值是在xdebug.ini配置的。 再点击run, Debug 'xxx'就可以调试了。 我在调试的时候发现PHPStorm时不时断点,提示错误:Remote file path '/var/www/xxxxx artisan' is not mapped to any file path in project,这是因为XDebug也会调试php cli,如果不需要可以关掉: 进入workspace容器docker-compose exec workspace bash。 编辑cli的xdebug.ini,nano /etc/php/7.4/cli/conf.d/xdebug.ini,注意你自己的PHP版本,修改两项配置:xdebug.remote_autostart=0 xdebug.remote_enable=0 保存退出就好了,不会再调试php cli了。需要的时候再打开好了。 配置后所有laradock容器中的站点全部都有效。你可以试着访问容器中其他站点,当前项目也会进入调试模式,而且PHPStorm又出现错误:Remote file path '/var/www/xxxxx' is not mapped to any file path in project。因为当前目录映射找不到。要重新打开其他项目,配置下目录映射,然后再开启动调试,不要开多个PHPStorm一起调试,会疯掉的。 结语 在这里浪费不少时间,确实够折腾的,不过确实长记性了,最近又开始折腾Laravel nova,2018年刚出的时候确实很多不完善,一直使用Laravel admin,总得来说还是没有Laravel nova那么舒服。现在Laravel nova经过那么长时间过度已经很完善了,是时候使用Laravel nova继续折腾了。
-
Laradock-部署本地开发环境 前言 之前laravel开发环境一直都是homestead部署,最近发现docker蛮火的。这段时间没什么事,稍微研究了一番。 首先需要理解docker给我们解决了什么问题。 对于开发者来说,最重要的就是轻便。docker中的容器将每个进程单独分割,互不影响但又有使用关联。很神奇,试想一下homestead,它是一台虚拟机,一旦启动就会占用固定的资源,哪怕资源在虚拟机中没有使用,你也是无法干预的,在虚拟器启动的那刻就已经分配。这种情况会造成很多资源浪费。 使用docker,把每个应用/服务都单个放入容器中,不会占用固定资源。更多空闲资源可以被系统利用,不会浪费掉。 其实docker最大的特点是解决部署时的方便。项目上线需要生产环境,特别是分布式服务器,每台都要独立安装,但是使用docker部署起来就会相当方便,编写好docker-compose.yml 和各个 服务/应用的 Dockerfile 文件,几行命令就能部署好整个生产环境。 以上是我目前对docker的愚解。 安装docker 这部看docker文档就好了,很详细。 我是用的是windows,安装程序下一步... windows系统和MacOS使用安装程序不需要单独安装docker-compose。 安装laradock 其实laradock文档中也很详细,直接clone代码就好了。 说说cp env-example .env文件吧。 ### 主要是项目目录,你开发项目所在目录,如果在同目录下(多项目配置)则不用动 APP_CODE_PATH_HOST=../ ### 项目在容器中挂载路径 APP_CODE_PATH_CONTAINER=/var/www ### 这个比较重要,数据卷存方位置,例如你的mysql数据库文件,redis持久化文件等(windows在C:\Users\用户名\.laradock\data) DATA_PATH_HOST=~/.laradock/data ... ### workspace这个大项中,很多开发者用不到 ### 像是PYTHON,NODE等我都会不安装 ### 服务器上部署也是,不需要尽量别安装 WORKSPACE_INSTALL_NODE=true ### 开启zsh SHELL_OH_MY_ZSH=true ### 开发环境需要XDebug就开启(反正我是需要) WORKSPACE_INSTALL_XDEBUG=true ... ### php版本 PHP_VERSION=7.4 ... ### 是否修改源,没翻墙还是需要 CHANGE_SOURCE=false ### ubuntu源 UBUNTU_SOURCE=aliyun ... ### php5.6含一下注意,redis扩展不支持,会报错 PHP_FPM_INSTALL_PHPREDIS=true ### 如果WORKSPACE_INSTALL_XDEBUG=true 开启了 ### 那么这边也需要开启 PHP_FPM_INSTALL_XDEBUG=true ... ### 把我坑惨了,Supervisor是php-woker提供的,配置文件也在里面,如果不开启的话,php-woker容器中的php是不包含redis扩展的 PHP_WORKER_INSTALL_REDIS=true ... ### mysql配置,按自己需求该 MYSQL_VERSION=5.7 MYSQL_DATABASE=homestead MYSQL_USER=homestead MYSQL_PASSWORD=secret ### mysql外部端口,本地我已经装了mysql 3306、33060都已经被占用 MYSQL_PORT=33061 MYSQL_ROOT_PASSWORD=root ### 这里是多数据库配置,laradock/mysql/docker-entrypoint-initdb.d目录下对照样本加 MYSQL_ENTRYPOINT_INITDB=./mysql/docker-entrypoint-initdb.d ... ### nginx配置 NGINX_HOST_HTTP_PORT=80 NGINX_HOST_HTTPS_PORT=443 ### 日志 NGINX_HOST_LOG_PATH=./logs/nginx/ ### 多站点配置目录,找样本加 NGINX_SITES_PATH=./nginx/sites/ NGINX_PHP_UPSTREAM_CONTAINER=php-fpm NGINX_PHP_UPSTREAM_PORT=9000 NGINX_SSL_PATH=./nginx/ssl/ ... 如果你开启了oh-my-zsh,默认是没有任何插件的,皮肤也是默认,laradock没有露出.zshrc配置文件文件,只能修改workspace的Dockerfile文件了,在Dockerfile文件找到下面代码(我是按照之前写得一篇文章oh-my-zsh强大的zsh配置管理配置安装的): ########################################################################### # Oh My ZSH! ########################################################################### USER root ARG SHELL_OH_MY_ZSH=false RUN if [ ${SHELL_OH_MY_ZSH} = true ]; then \ apt install -y zsh \ ;fi USER laradock RUN if [ ${SHELL_OH_MY_ZSH} = true ]; then \ sh -c "$(curl -fsSL https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh) --keep-zshrc" && \ git clone https://github.com/zsh-users/zsh-autosuggestions ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-autosuggestions && \ git clone https://github.com/zsh-users/zsh-syntax-highlighting.git ${ZSH_CUSTOM:-~/.oh-my-zsh/custom}/plugins/zsh-syntax-highlighting && \ sed -i -r 's/^plugins=\(.*?\)$/plugins=(laravel5 zsh-syntax-highlighting zsh-autosuggestions)/' /home/laradock/.zshrc && \ sed -i -r 's/^ZSH_THEME=\".*?\"$/ZSH_THEME="ys"/' /home/laradock/.zshrc && \ echo '\n\ bindkey "^[OB" down-line-or-search\n\ bindkey "^[OC" forward-char\n\ bindkey "^[OD" backward-char\n\ bindkey "^[OF" end-of-line\n\ bindkey "^[OH" beginning-of-line\n\ bindkey "^[[1~" beginning-of-line\n\ bindkey "^[[3~" delete-char\n\ bindkey "^[[4~" end-of-line\n\ bindkey "^[[5~" up-line-or-history\n\ bindkey "^[[6~" down-line-or-history\n\ bindkey "^?" backward-delete-char\n' >> /home/laradock/.zshrc \ ;fi 可以自定义安装插件,修改皮肤。git clone ...下载插件,记得在sed -i -r 's/^plugins=\(.*?\)$/plugins=(laravel5 zsh-syntax-highlighting zsh-autosuggestions)/' /home/laradock/.zshrc && \中加载你的插件,sed -i -r 's/^ZSH_THEME=\".*?\"$/ZSH_THEME="ys"/' /home/laradock/.zshrc && \ 修改皮肤(例如我这里修改的是ys皮肤,echo '\n\ ...默认绑定了一些快捷键,不需要可以删掉。有兴趣可以查看我的文章oh-my-zsh强大的zsh配置管理)。 其他没什么安装需要注意的了,执行: ### 启动容器 mysql redis nginx php-worker ### -d参数是后台运行 docker-compose up -d mysql redis nginx php-worker workspace、php 默认会自己启动,因为容器都依赖它们 如果你没有修改COMPOSE_FILE=docker-compose.yml配置文件的话,laradock项目中所有镜像全部会安装 !!!0.0!!!。 启动之后你可以进入容器: ### 就像虚拟机一样,很亲切 ### 像composer,git等命令都有,不需要单独安装 docker-compose exec workspace bash 进入workspace后执行: cd 你的项目名称/ php artisan migrate ... workspace可以换成你想操作的(已经启动)任何容器名称(mysql,nginx...),非常方便操作。 并非完美 laradock在修改配置后重新docker-compose build xxx又会重新安装/编译一次,非常耗时,特别是workspace容器,简直恐怖。这点没有虚拟机来得方便。 docker在MacOS中存在文件读取缓慢的问题。 mysql或者其他数据库在容器中部署还存在一定的安全隐患。 结语 其实自己手动折腾一遍之后并不像想象中那么难。 仔细查看Dockerfile文件后你会发现里面就是各种安装部署命令,只是用docker特定的语法包裹了。docker安装容器就是执行你编写好的命令。 服务器部署直接一套docker就搞定,而且服务器项目比较杂的话非常适合,毕竟各种项目(php,java,python...)环境在服务器上搭建难免出现奇奇怪怪的问题,在容器中的话互不干扰,横向扩展服务器简直不能再方便了。
-
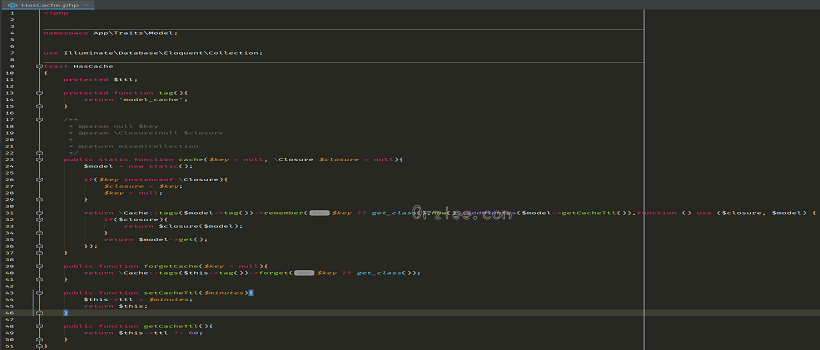
实用-模型缓存trait 前言 好久没有写博客了,赖癌看来又发作了。也没有很高大上的东西写,就写写自己开发中比较顺手的小知识吧! 开发中经常会有些模型读取非常频繁,但是又很少做写入修改操作(类似于 分类、品牌等),这种情况缓存简直不能再好了,既可以大量减少数据库压力,又可以非常快速读取(前提要配置好缓存,比较推荐redis)。 Trait 如果你连trait都不认识的话好好看看文档吧。 起初最简单的思路就是能简单方便的让模型可以缓存和读取。laravel已经有了非常好用的缓存系统,非常方便,但是相对还可以封装一下,让模型缓存更加优雅。 代码非常简单,我就不多废话了: namespace App\Traits\Model; use Illuminate\Database\Eloquent\Collection; trait HasCache { protected $ttl; protected function tag(){ return 'model_cache'; } /** * @param null $key * @param \Closure|null $closure * * @return mixed|Collection */ public static function cache($key = null, \Closure $closure = null){ $model = new static(); if($key instanceof \Closure){ $closure = $key; $key = null; } return \Cache::tags($model->tag())->remember($key ?? get_class(),now()->addMinutes($model->getCacheTtl()),function () use ($closure, $model) { if($closure){ return $closure($model); } return $model->get(); }); } //删除缓存 public function forgetCache($key = null){ return \Cache::tags($this->tag())->forget($key ?? get_class()); } //设置缓存时间 public function setCacheTtl($minutes){ $this->ttl = $minutes; return $this; } public function getCacheTtl(){ return $this->ttl ?: 60; } 使用 我这是使用的laravel-admin后台,有兴趣可以了解下,极大节约后台程序开发周期。 在需要缓存的模型中使用HasCachetrait: class ProductCategory extends Model { use SoftDeletes, ModelTree, AdminBuilder, HasCache; ... //也可以自己扩展缓存自己想要的数据 public static function levelCache(){ return self::cache(get_class().'level_cache', function ($model){ $sort_closure = function ($query){ $query->sort(); }; return $model->with(['children' => $sort_closure,'children.children' => $sort_closure])->where('parent_id',0)->sort()->get(); }); } //对应的删除缓存方法 public static function forgetLevelCache(){ return (new static())->forgetCache(get_class().'level_cache'); } } 后台控制缓存,在更新、添加数据后及时清除缓存,防止脏读,虽然是缓存但是还是要保证数据及时性吧!(例子中使用的是laravel-admin扩展) /** * Make a form builder. * * @return Form */ protected function form() { $form = new Form(new ProductCategory); $form->display('id','ID'); ... $form->saved(function (Form $form){ //模型保存成功后的回调函数中删除缓存 $form->model()->forgetLevelCache(); }); return $form; 如果没有使用laravel-admin,可以手动删除缓存或者监听模型保存成功事件,laravel-Eloquent:Events。 平时使用: ProductCategory::levelCache(); ProductCategory::setCacheTtl(30)->cache() ProductCategory::cache(function(ProductCategory $model){ ... return $model->get(); //返回你想保存的数据 }) 结语 模型缓存后使用起来更加简单了,千万别把服务器内存玩爆了。开发中很多小技巧自己都没有好好总结,然后多了再总结就懒癌发作,哎!
-
laravel-admin 与 laravel-nova 使用感受 前言 两种后台管理扩展我都使用过,两个扩展既有很多相似点,却又有很多不同。接触过laravel nova之后,再接触laravel admin有种莫名的熟悉感,发现在开发中有很多类似的设计思路。 接触laravel admin时间只有一个来月,时间还不长,随便写写吧。有不足之处还请多多指教。 感受 其实laravel nova就是laravel admin的进化版,显然laravel admin是开源扩展,而laravel nova是付费使用的(99刀一个授权可不便宜),在这不考量两者使用授权方面。 laravel admin是一个中国开发者,做出这样的扩展确实非常了不起。扩展设计合理,但是优化上没有laravel nova那么好。 其实最开始接触laravel nova之前是考虑过laravel admin的,由于laravel admin已经封装好了权限管理,自己替换处理又相对麻烦(其实就是懒),才放弃的。laravel admin的权限管理没有做缓存处理,每次使用都要从数据库查询,其实完全可以缓存起来减轻数据库压力。相对于laravel nova这个功能已经交给开发者实现(我还写过一篇关于 laravel nova 权限管理 的文章)。类似于这样需要缓存的还有菜单功能,因为网站上线后这些几乎不变的的数据却又频繁读取,缓存能解决不少数据库压力(有时间自己处理下)。 laravel admin模板还是使用HTML(对于我这种前端弱的一逼的程序员来说真是非常友好),而laravel nova使用vue.js,相对来说vue.js体验感更好,但是技术要求也相对较高。折腾vue.js多多少少还是要翻几次文档。在扩展字段的时候前端模板就相当重要了(反正我写的CSS无法直视)。 laravel admin更加符合国人操作习惯,我使用admin LTE开发过几个后台,基本上不需要教如何使用,大多数功能、按钮一目了然。而laravel nova很多功能、按钮藏的比较深,很多同事反映过找不到地方... 在代码层面,laravel admin我总感觉没有laravel nova那么简洁、灵活。列表页,详情页,编辑页总共需要些三个不同的模板,我是用laravel localization本地化功能,所以需要将三个模板全部修改翻译,而laravel nova只需要编写一次模板,不需要在某个页面显示的字段可以单独关闭: //laravel admin 列表页、详情页、表单,其实还需要三个控制器动作分别输出不同的模板 /** * Make a grid builder. * * @return Grid */ protected function grid() { $grid = new Grid(new ProductSpecification); $this->gridViewPermission($grid); $grid->id('Id')->sortable(); $grid->name(trans('product/specification.name'))->sortable(); $grid->created_at(trans('admin.created_at'))->sortable(); $grid->updated_at(trans('admin.updated_at'))->sortable(); return $grid; } /** * Make a show builder. * * @param mixed $id * @return Show */ protected function detail($id) { $show = new Show(ProductSpecification::findOrFail($id)); $this->showViewPermission($show); $show->id('Id'); $show->name(trans('product/specification.name')); $show->attributes(trans('product/specification_attribute.index'),function (Grid $attributes){ $this->gridViewPermission($attributes); $attributes->setResource(route('admin.product.specification.attribute.index')); $attributes->id()->sortable(); $attributes->name(trans('product/specification_attribute.name'))->sortable(); $attributes->created_at(trans('admin.created_at'))->sortable(); $attributes->updated_at(trans('admin.updated_at'))->sortable(); }); $show->created_at(trans('admin.created_at')); $show->updated_at(trans('admin.updated_at')); return $show; } /** * Make a form builder. * * @return Form */ protected function form() { $form = new Form(new ProductSpecification); $this->formViewPermission($form); $form->text('name', trans('product/specification.name')) ->rules('unique:product_specifications') ->required(); $form->hasMany('attributes', trans('product/specification_attribute.index'), function (Form\NestedForm $form){ $form->text('name',trans('product/specification_attribute.name'))->required(); }); $form->saved(function (Form $form){ $form->model()->forgetCache(); }); return $form; } ... //laravel nova 表单、列表、详情 public function fields(Request $request) { $guardOptions = collect(config('auth.guards'))->mapWithKeys(function ($value, $key) { return [$key => __('nova-permission-tool::roles.guard_names.'.$key)]; }); $userResource = Nova::resourceForModel(getModelForGuard($this->guard_name)); return [ ID::make()->sortable(), Text::make(__('nova-permission-tool::roles.name'), 'name') ->rules(['required', 'string', 'max:255']) ->creationRules('unique:'.config('permission.table_names.roles')) ->updateRules('unique:'.config('permission.table_names.roles').',name,{{resourceId}}'), Text::make(__('nova-permission-tool::roles.guard_name'), function () { return __('nova-permission-tool::roles.guard_names.'.$this->guard_name); }), Select::make(__('nova-permission-tool::roles.guard_name'), 'guard_name') ->options($guardOptions->toArray()) ->rules(['required', Rule::in(array_keys($guardOptions->toArray()))]) ->onlyOnForms(), DateTime::make(__('nova-permission-tool::roles.created_at'), 'created_at')->exceptOnForms(), DateTime::make(__('nova-permission-tool::roles.updated_at'), 'updated_at')->exceptOnForms(), BelongsToMany::make(__('nova-permission-tool::resources.Permissions'), 'permissions', Permission::class)->searchable(), MorphToMany::make($userResource::label(), 'users', $userResource)->searchable(), ]; } 通过以上代码对比可以看出两个扩展在代码简洁性上有蛮大区别的。一个个字段写入翻译蛮麻烦的。在关系字段处理上需要关联表的控制器,然后增删改查又是一套... 当然这样也是有好处的,高度自定义,只不过一个后台管理用处不多,大多数可以自定义字段扩展出来。 laravel admin几乎把所有字段所需的 javaScript放在后端输出,其实这样对前端不友好,现在都前后端开始分离了,前端代码放在PHP中嵌套写蛮乱的,后期维护也相对困难。 结语 laravel nova和laravel admin都是非常好的扩展,只是国内大多数只知道拿人家的用,却很少去贡献,生态不如国外。两个扩展都朝着相同的目标,节省后台开发时间,但是一个收费,一个开源,而且laravel nova还是laravel作者团队开发的(框架加持)。扩展都是好扩展,要按项目需求和自己的熟练程度来选择使用哪种扩展开发后台,有能力两种都试试,深深体会一下。
-
微擎-mysql数据库崩溃 前言 公司目前有两个微擎搭建的商场项目,是购买的插件。就在前几天出现MySql数据库崩溃,出现 mysql too many connection 的错误,在修复过程发现这个微擎就是个巨坑。 修复过程 orzlee使用的是 MySql 5.7 最开始以为访问量太大,调整下MySql配置文件中的 max_connections 选项,然后重启数据库。服务器配置8核16G,目所有站点前访问量足够应付。 调整 max_connection 后不到十分钟,问题依旧出现。进入数据库,使用命令查看当前所有连接: show processlist; 一看吓一跳,两个微擎数据库全部锁表,由于站点一直在访问,链接数只增不减,难怪数据库崩掉。锁表问题很好解决,进入数据库解锁就好了: use database; ##database 是数据库名称 unlock tables; 然后并没有解决根本问题,真正的问题是 ims_core_sessions 表索引坏了,微擎自己自检表状态并且执行修复 repair table ims_core_sessions。而且 ims_core_sessions 表读写相当频繁,这样一来后面的查询全部堵塞。 解决办法 解决办法很简单,先把两个微擎系统停掉。orzlee是修改nginx配置文件,停止解析当前两个微擎的业务域名,然后进入数据库手动修复 ims_core_sessions 表索引,大约有个7、8分钟才修复完成: use database ##database 数据库名称 repair table ims_core_sessions; 在数据连接超出之后,已连接的查询全部会挂起,所以微擎根本不可能修复完成。这也是导致所有站点全挂的主要原因。 结语 这种问题以后肯定还会出现,坑已经填上了。数据库引擎还是使用 innoDB 的好。MySql官方已经使用 innoDB 作为默认数据库引擎。
-
微信-域名被封监测以及自动更换被封域名 前言 微信已经成为大多数中国人的一种依赖,发展好了自然管理就更加严格,对于不符合微信营销规范的的网站统统不允许访问,就连对手的网址也无法在微信浏览器中打开。 最近公司有个需求,在各个平台大量投放广告,微信内域名频繁被封,需要域名监测和替换的内部系统功能。微信开发做过不少,但是这种明显是找漏子钻。 想不到就上网找吧!把Google翻个底朝天,全TMD是广告,各种出租微信域名防封检测API,真的一条有用的信息都没有。这下真得靠自己了。 那些出售API的到底是用的什么方法? 我琢磨了一会,想不到还能又什么方法能检测域名是否被微信封掉,只有在微信APP或桌面微信内置浏览器才行啊。抓包看看请求域名前有没有什么检测API,也没有发现什么有价值的信息。后来想想也不可能写个程序,人家请求API检测域名就用程序在桌面微信打开链接判断是否被封吧。真的有点悬,这难道有内部接口? 我是如何找到方法的? 在年中的时候我发现一个微信很坑爹的问题,那时候在高铁上改代码历历在目。“微信短链接”把orzlee坑惨了,在公司内部系统做了个短链接功能,每次手动替换被封域名都会自动生成微信短链接,这下倒好,生成的短链接不到一小时就封,替换了好几个域名,最后用长连接明显存活时间更长。 最坑爹的还不是这个,微信短链接跳转域名被封,短链接在任何浏览器打开都会如下提示: 功能编写思路 Nice,有办法了,我把需要检测的域名都生成一个微信短链接,然后隔段时间访问短链接判断是否重定向正确的域名或者判断重定向域名是否weixin110.qq.com。 整套功能编写思路: 域名都在阿里云,充分利用域名分组功能,总共分三组域名池-正常使用域名-弃用域名。整套域名管理使用API处理 域名池 域名池域名无任何指向,完全未使用的正常域名(没有被微信封,有指向也可以,那就再替换域名逻辑要做好处理了)。 正常使用域名 目前正常使用的域名 弃用域名 已经被微信封或者域名备案丢失 每隔一段时间检测域名是否正常,这个有两种情况: 域名正常 皆大欢喜(^_^)。 域名被封(备案丢失) 替换被封域名 说说被封的处理思路,因为公司内部系统已经自动化站点配置,现在加入阿里云API简直如虎添翼。域名替换使用固定短链接,要求使原域名链接依然可以正常访问。这点很好做,302重定向即可。域名使用记录表中记录新域名,旧域名被访问(使用以一个域名专门用作跳转域名,不做其他使用,携带参数能找到数据库中的旧域名。这个域名最好自己注册备案一个),重定向至新域名,固定链接不会变动,使用缓存减轻服务器压力。 移动被封域名至弃用域名分组 域名池取出域名移动至正常使用域名 分组 添加域名解析 修改nginx配置新域名 记录已经替换的新域名(同一条数据多一个new_domain字段,一旦换新域名就替换。也可以直接替换,只是之前配置的旧域名就找不到了,看业务需求吧) 这样整个思路就很清晰了。 核心功能 有了思路就简单多了,准备开搞。 我把监测功能写成laravel command,方便自己使用,任务调度也没问题。 在测试监测代码时发现一个问题,访问频率太快容易403。尝试替换User Agent,client-ip等头部信息没用。最后只有一个办法了,HTTP代理。网上虽然有很多免费的,但是这东西不稳定那就是自己刨坑,公司有几台服务器,全部搭建HTTP代理,都是以前购买的阿里云服务器,就为了备案而买的。 搭建HTTP代理 安装tinyproxy sudo apt-get update sudo apt-get install tinyproxy 编辑配置文件: Port 8888 代理端口可自己修改 Allow 127.0.0.1 填写需要使用代理的服务器IP,只有该IP的服务器才能访问 nano /etc/tinyproxy.conf Ctrl+o 保存 Enter 确认 Ctrl+x 退出编辑器 启动重启停止命令 service tinyproxy start service tinyproxy restart service tinyproxy stop 阿里云服务器无备案检测 阿里云服务器配置未备案服务器会返回403状态码,按照状态码判断是否无备案。这里就需要保证域名池中的域名是无解析或者有解析但是配置正确,绝对不能自己搞出个403误判,这点应该是没问题的。 代码编写 use GuzzleHttp\Client; use GuzzleHttp\Exception\ConnectException; use Illuminate\Console\Command; use Illuminate\Http\Response; use Illuminate\Support\Facades\Event; use Lijianmin\DomainDetection\Events\BanDomainEvent; use Lijianmin\DomainDetection\Models\Domain; class DomainMonitorCommand extends Command { /** * The console command name. * * @var string */ protected $name = 'domain-detection:monitor'; /** * The console command description. * * @var string */ protected $description = 'monitor domain name is ban.'; const SLEEP_TIME = 2; const USER_AGENTS = [ "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)", "Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", "Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)", "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)", "Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)", "Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)", "Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0", "Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5", "Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20", "Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52", ]; const PROXY = [ '', //本机 ... //自己搭建的代理 ]; /** * Execute the console command. * * @return void */ public function handle(Client $client) { //找出正在使用的域名,阿里云域名API获取域名列表,存入数据库。表中'detail'字段我保留了API返回的当前域名原始信息。 //'short_url'字段为保存时生成的微信短链接 $query = Domain::whereNotNull('short_url') ->where(\DB::raw("detail->'$.DomainGroupId'"), config('domain_detection.ali.group_id')) ->where('status', true); foreach ($query->cursor() as $index => $domain) { $result = $client->get($domain->short_url, [ 'allow_redirects' => false, 'headers' => [ 'USER-AGENT' => array_random(self::USER_AGENTS), //获取随机'USER-AGENT' ], 'proxy' => array_get(self::PROXY, ($index % count(self::PROXY))), //循环使用使用代理 'http_errors' => false, //屏蔽4xx 5xx状态码异常 ]); //访问微信短链接,获取重定向域名 $redirect_domain = $this->extractDomain($result->getHeaderLine('Location')); //如果重定向域名是否与当前数据域名匹配,否则被封了 if (strpos($redirect_domain, $domain->domain) !== false) { try { //微信没封再来检测备案 if ($client->get($redirect_domain, [ 'http_errors' => false, 'allow_redirects' => false, //如果无备案域名配置在当前服务器,自己访问是正常的,一定要其他主机访问才会返回403 'proxy' => last(self::PROXY), ])->getStatusCode() != Response::HTTP_FORBIDDEN) { $domain->touch(); //更新updated_at 时间戳,刷新最近检测时间 sleep(self::SLEEP_TIME); //HTTP代理比较少,频率低点比较好 continue; } } catch (ConnectException $exception) { if ( !$exception->getCode()) { $domain->touch(); sleep(self::SLEEP_TIME); continue; }; throw $exception; } } //被封了或者掉备案了,标记状态 $domain->status = false; $domain->save(); //这个事件主要处理域名更换操作,移动阿里云域名分组等等 Event::fire(new BanDomainEvent($domain)); sleep(self::SLEEP_TIME); } } // 提取连接中域名 public function extractDomain($url) { if (empty($url)) { return ''; } return array_get(parse_url($url), 'host'); } } 阿里云API看文档就好了,阿里云API-PHP-composer,对照文档使用。 提醒下API类: 例如http://domain.aliyuncs.com,看域名前缀找API。找到需要的API类后链式调用就API名称就好了,其实蛮友好的,只是文档没有说明。 //http://domain.aliyuncs.com AlibabaCloud::domain()->v20180129()->updateDomainToDomainGroup() //http://domainIntl.aliyuncs.com AlibabaCloud::domainIntl()->v20171218() 结语 幸好被微信短链接坑过,才会长记性,遇到其他问题居然把坑给利用起来了。其实核心就一个,用微信短链接来判断域名是否正常是目前想到的最简单的放法了,也不知道那些出售API的是不是有更好的方法,如果需求量大的话就找更多的HTTP代理,不然还是有点担心代理不够用,到时候全是403,不过403解封状态也很快,但是这种硬杠的做法还是不好,代理越多保证万无一失。